
Datový typ LIST a jak ho chytře využít
- 28. 7. 2016
- Minut čtení: 3
Jelikož jsem na internetu nenašel řešení, jak mnou požadovaným způsobem iterativně tvořit list obsahující výstup ve formátu data.frame, tak po rozřešení problému vlastními silami, jsem si říkal, že se o tuto „vychytávku“ podělím. Obecné povídání o datových typech v R by bylo určitě vhodné začít od základů, tedy od těch nejjednodušších struktur, ale tentokrát volím trochu jiný přístup. Jednak z toho důvodu, že většina datových typů kromě toho v záhlaví zmíněného a asi class RAW jsou poměrně často využívané a pravděpodobně je dobře znáte, jednak z důvodu jejich celkové nezáludnosti. Věnujme jim proto jen pár vět.
Rko využívá následující datové typy (od hierarchicky nejnižšího):
VECTOR (kombinuje následující elementy/třídy – classes)
LOGICAL (TRUE/FALSE)
NUMERIC (1,2,3)
INTEGER (2L, 3L)
COMPLEX (3+2i)
CHARACTER (1,2, a, b)
RAW (velmi speciální formát, více viz zde)
FACTOR (kategoriální proměnná nebo databázově dimenze)
MATRIX (kombinuje vektory jako řádky nebo sloupce)
DATA.FRAME (na rozdíl od matice může kombinovat vektory různých tříd, dataset)
LIST (kombinuje všechny předchozí typy, může obsahovat celý data.frame, funkci nebo i sebe sama jako svůj prvek)
Další velmi důležitou věcí, kterou rozbor datových typů uzavřeme, je jejich „donucování/konverze“ (coercion). To je operace, kterou R automaticky provede v závislosti na tom, jaký je vstup. Odehrává se následovně (od nejvíc specifických k nejvíce obecným):
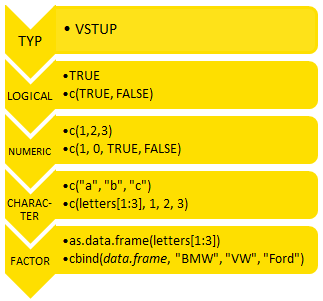
Teď už k samotnému typu LIST. Je to, dá se říct, obecný vektor, který může jako svoje složky obsahovat objekty jiných tříd. Z toho plyne několik odlišností v zacházení s listy, ale i výhod. Z počátku se může zdát jako překomplikovaný a „nešikovný“, ale jak jste si mohli všimnout, výstupy z funkcí a odhadů modelů jsou právě ukládány jako list a po prvotním osvojení Vám listy naopak přijdou velmi šikovné.
List má prvky několika úrovní (dimenzí), není to jen řádek a sloupec, ale také tzv. slice neboli řez. Z toho důvodu se jinak volají jeho prvky. Vytvoříme testovací LIST a nejdříve prvky pojmenujeme. To se dá provést pomoci funkce name().
Pro vyvolání řezů se používají dvojité hranaté závorky [[ ]], tedy např. pro náš list jsem_list:
Nebo také dle názvu (stejně jako sloupce v data frame):
Pro vyvolání konkrétního sloupce data.frame v našem listu musíme už použít dvojitý index [[ ]][ ], [[ ]] [„col_name“] nebo $name[ ], resp. $name[„col_name“]:
A teď už avízovanému chytrému využití. Problém, který jsem řešil, tkvěl ve vrácení více objektů jako výsledek vlastní funkce. To v R standardně nejde, funkce vrací objekt z posledního řádku jejího kódu. Lze to obejít přes vytvoření nového prostředí (environment) a ukládat to tam. Rovněž výstup, který jsem potřeboval, měl být poměrně jednoduše dále zpracovatelný také i iterativně (ve for cyklu). Vhodnou strukturou se tedy zdál list, ale chvíli trvalo přijít na to, jak do listu iterativně chytře ukládat. V příkladu dole označíme jako výstup kalkulace v každém kroku for cyklu objekt result a jako celkový výsledek objekt result_list. Intuitivní způsob napovídá to realizovat takto:
To však bude ukládat celý předchozí výsledek result_list jako první element a result jako druhý. Tedy na konci bude v prvním elementu listu zmeť nepřehledných indexů.
Elegantnějším a dokonce (ve finále) i zdánlivě intuitivnějším řešením se jeví jiný způsob, který se mi právě na StackOverflow a jiných zdrojích najít nepodařilo. Tím je následující zápis:
Plný příklad pro výpočet pro každou proměnnou v datasetu by mohl vypadat následujícím způsobem:
Výstupem je pak:

Závěrem: LIST může být velmi šikovný a nápomocný způsob, jak ukládat výstupy a data, a tedy absolutně netřeba se ho bát. Chce to jen chvilkové osvojení, trochu praxe s tvorbou a použitím a máte to "v prstech". Už budete jen těžit z jeho výhod a v některých aplikacích pravděpodobně jiný datový typ používat ani nebudete chtít.
Přeji dobrou zábavu při zkoušení a osvojování.




Komentáře